Public note
TurboQuant Explained Simply: The Easiest Way to Understand the Paper After Learning Inner Product and Quantization
TurboQuant is a method for compressing high-dimensional vectors in LLM KV caches while preserving inner product relationships critical for attention mechanisms, using a two-stage approach with QJL correction.
Meta description: A beginner-friendly explanation of TurboQuant for readers who already understand inner product and quantization. Learn why TurboQuant matters for LLM KV cache compression, how it works, and what makes it different from standard low-bit quantization.
Why This Article Exists
If you already understand these two ideas:
- inner product tells us how strongly two vectors align, and
- quantization compresses vectors by storing them with fewer bits,
then you are ready for the main idea behind TurboQuant.
This article explains TurboQuant as simply as possible.
The goal is not to reproduce every theorem in the paper. The goal is to help you answer these practical questions:
- What problem is TurboQuant trying to solve?
- Why is ordinary low-bit quantization not enough?
- What is the core trick in TurboQuant?
- Why does it help with LLM inference and vector search?
If you finish this article with one mental model, it should be this:
TurboQuant is a way to compress vectors very aggressively while trying hard not to break the inner products that attention and retrieval depend on.
The Problem in One Sentence
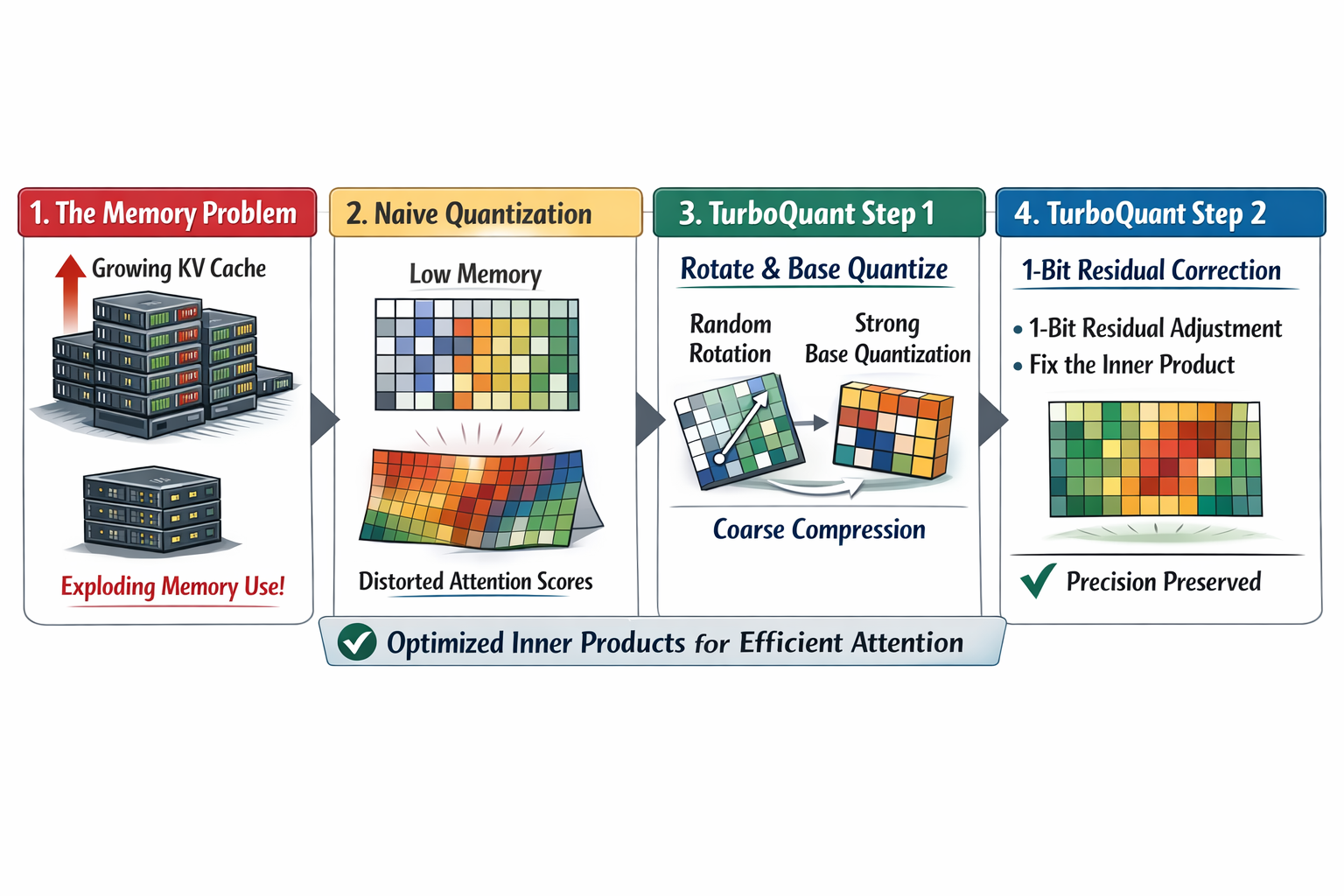
Modern LLMs keep a large KV cache during generation, and that cache grows with the context length.
That creates a memory bottleneck.
A natural idea is to quantize the KV cache into fewer bits. But if you compress keys and values too naively, you can distort the inner products that attention uses:
And once those scores shift too much, the model may attend to the wrong tokens.
So the real problem is not just:
How do we make the cache smaller?
It is:
How do we make the cache smaller while preserving the relationships that attention actually needs?
That is the TurboQuant problem.
Where TurboQuant Fits in the Story
You can think of the full story as a three-step ladder.
Step 1: Inner Product
Attention is driven by vector interactions such as:
So preserving inner products matters.
Step 2: Quantization
We can reduce memory by storing vectors with fewer bits, but that introduces error.
Step 3: TurboQuant
TurboQuant asks:
Can we quantize vectors at very low bit-widths while preserving the inner-product structure well enough that LLM quality stays almost the same?
That is why TurboQuant is not just "yet another compression method." It is a compression method designed around the geometry that downstream computations care about.
Why Standard Quantization Is Not the Full Answer
A simple quantizer often tries to reconstruct the original vector as closely as possible.
In other words, it tries to make:
with small mean-squared error:
That is useful, but it is not always enough.
Why?
Because attention does not directly care about MSE. It cares about the score computed from the query and key.
A quantized key may look numerically close to the original key, yet still shift:
by enough to change which tokens get attention.
So TurboQuant starts from a more task-aware viewpoint:
Do not only preserve values. Preserve the interactions that matter.
The Beginner-Level Summary of TurboQuant
TurboQuant is easiest to understand as a two-stage compression strategy.
Stage 1: Use most of the bits to make a strong first approximation
First, TurboQuant creates a good compressed version of the vector.
Very loosely, the system does something like this:
- it transforms the vector into a form that is easier to quantize,
- it uses most of the bit budget to capture the main shape and strength of the vector,
- it leaves behind a smaller residual error.
You can think of this as:
where:
- is the main compressed approximation,
- is the leftover residual error.
If this were the whole method, it would already be a good MSE-oriented quantizer.
But TurboQuant does not stop there.
Stage 2: Spend 1 extra bit on the residual to fix inner-product bias
This is the clever part.
The paper argues that even a good MSE quantizer can still be biased for inner-product estimation.
So TurboQuant uses a second step: it applies a 1-bit QJL-style correction to the residual.
That extra 1-bit stage is not trying to reconstruct every detail of the original vector. It is trying to correct the part that most harms inner-product estimation.
So the big picture is:
- use most bits to get a strong base approximation,
- use 1 more bit to make the inner-product estimate much more trustworthy.
That is the heart of TurboQuant.
A More Intuitive Mental Model
Imagine you compress a photo.
A normal compressor might focus on making the new image look visually close to the old one on average.
TurboQuant is closer to saying:
- first, keep the main structure of the image,
- then spend a tiny extra budget to protect the edges and features that a recognition system cares about most.
In LLMs, those critical "features" are not pixels.
They are the vector relationships used by attention and retrieval.
So TurboQuant is not trying to make every coordinate perfect.
It is trying to make the compressed vector still behave correctly when multiplied against queries.
What Does the Random Rotation Do?
One part of the paper sounds more mathematical than it really needs to for intuition.
TurboQuant first applies a random rotation to the vector.
Why do that?
Because real vectors often have awkward coordinate patterns. Some dimensions may be heavy, some light, and simple coordinate-wise quantization may work poorly.
A random rotation spreads the information more evenly across coordinates.
That makes it much easier to apply simple scalar quantization per coordinate.
A beginner-friendly way to think about it is this:
If the information is packed into awkward directions, rotate the space so the vector looks more regular before compressing it.
This is one reason TurboQuant can stay simple and still work well.
What Is QJL Doing in Plain English?
TurboQuant uses QJL, short for Quantized Johnson-Lindenstrauss, as the second-stage correction on the residual.
At a very high level, QJL is a way to make a very cheap sketch of a vector while preserving the geometry needed for inner-product queries.
The blog explains it as a kind of compact shorthand built from only one sign bit per coordinate after a projection step.
For intuition, you do not need the full theorem.
You only need to remember this:
QJL is the tiny correction layer that helps TurboQuant avoid the inner-product bias that a plain MSE quantizer would leave behind.
That is why TurboQuant can be both very compressed and still strong on attention-related tasks.
Why the Paper Cares About “Unbiased Inner Product Estimation”
This sounds intimidating, but the idea is simple.
Suppose a quantizer tends to systematically make inner products too small or too large.
Then even if its average numeric reconstruction looks okay, attention scores can drift in a consistent direction.
The paper shows that MSE-optimal quantizers can have exactly this problem: they can be good at reconstruction but still bad in a more subtle way for inner products.
TurboQuant fixes that by combining:
- a strong first approximation, and
- a QJL residual correction that gives an unbiased inner-product estimator.
Beginner translation:
It is not enough to be close. You also do not want a systematic tilt in the attention scores.
Why TurboQuant Is Especially Interesting for KV Cache Compression
Weights are static. You quantize them once.
The KV cache is different:
- it grows during generation,
- it depends on the input and generated tokens,
- it directly affects attention,
- and it becomes a memory bottleneck for long contexts.
That makes KV cache compression a very practical problem.
TurboQuant is attractive here because it is designed to be:
- training-free,
- online or data-oblivious, meaning it does not require heavy data-dependent preprocessing,
- and friendly to efficient inference.
That combination matters in real systems.
A method can be theoretically strong, but if it needs heavy tuning or offline learning, it becomes less attractive for streaming inference.
TurboQuant tries to stay both mathematically grounded and operationally usable.
What “Near-Optimal Distortion Rate” Actually Means
This phrase sounds scary, but the simple version is manageable.
The paper proves lower bounds on how good any vector quantizer can be, in principle, at a given bit budget.
Then it shows TurboQuant comes close to that best-possible rate, within a small constant factor.
In plain English:
TurboQuant is not just empirically good. The authors argue it is also close to the best compression-versus-distortion tradeoff you could hope for, up to a constant multiplier.
That does not mean TurboQuant is magically lossless.
It means the amount of error it makes shrinks with bit-width in a way that is close to theoretically optimal.
For understanding the paper, that is enough.
What Results Should You Remember?
For a beginner-level understanding, you do not need every benchmark table.
You only need the main pattern.
1. It works well on KV cache compression
Google’s blog says TurboQuant can quantize the KV cache to 3 bits in its reported tests without training or fine-tuning and without hurting model accuracy, while also improving runtime in their setup.
2. The paper’s abstract gives a slightly more conservative summary
The paper abstract says TurboQuant achieves absolute quality neutrality at 3.5 bits per channel and marginal degradation at 2.5 bits per channel for KV cache quantization.
3. It also helps vector search
The paper is not only about LLM KV cache compression. It also shows strong nearest-neighbor search results, where TurboQuant outperforms existing product-quantization baselines in recall while making indexing time essentially negligible.
So the big message is:
TurboQuant looks useful both for long-context LLM inference and for vector database style search.
Why the Blog Mentions PolarQuant
If you read the Google Research blog, you will notice that it presents TurboQuant, QJL, and PolarQuant together.
That can be confusing at first.
A simple way to keep it straight is:
- QJL is the 1-bit residual correction idea,
- PolarQuant is another related compression idea from the same research line,
- TurboQuant is the full system the paper centers on.
For learning purposes, the safest beginner mental model is this:
TurboQuant uses a strong first-stage quantizer for the main approximation, then a 1-bit QJL pass on the residual to protect inner-product quality.
That is the essence you need.
Why TurboQuant Feels Different From “Just Use 4-Bit”
Many practical quantization discussions sound like this:
- use 8-bit if you want safety,
- use 4-bit if you want stronger compression,
- go lower only if you can tolerate quality loss.
TurboQuant is more ambitious.
It asks whether we can go into a much more aggressive bit regime and still keep the parts of the geometry that matter for downstream computation.
So TurboQuant is not just a smaller datatype.
It is a designed compression algorithm with a specific geometric objective.
That is what makes it interesting.
The Simplest Possible Step-by-Step View
If you want the entire paper reduced to a short workflow, use this:
- Start with a high-dimensional vector.
- Rotate it so the coordinates become easier to quantize.
- Use most of the bits to build a strong compressed approximation.
- Compute the leftover residual error.
- Use a 1-bit QJL sketch on that residual.
- Combine both parts so inner products are preserved much better than with naive low-bit quantization.
That is TurboQuant in the simplest operational form.
Why This Matters for Understanding the Research Paper
When you read the actual paper, there are three things that may otherwise feel abstract:
1. The theorems about distortion
These are there to prove the method is not just a trick that happens to work on one benchmark.
2. The emphasis on inner-product bias
This is there because attention depends on inner products, not just on raw vector reconstruction.
3. The use of a two-stage method
This is there because one stage handles the main approximation, while the second stage repairs what matters for inner products.
If you hold those three ideas in your head, the paper becomes much easier to read.
What You Should Not Over-Interpret
It is important to read the claims carefully.
TurboQuant is impressive, but the right interpretation is:
- it is a promising training-free quantization method,
- it shows strong results on long-context and vector-search tasks,
- it has theoretical backing,
- and it seems particularly good in very low-bit settings.
But it does not mean:
- every model in every deployment will automatically get identical results,
- quantization becomes free,
- or MSE no longer matters at all.
A better reading is:
TurboQuant is a strong answer to the specific problem of preserving geometry, especially inner products, under very aggressive compression.
The Main Takeaway
Here is the one-paragraph version.
TurboQuant is a vector compression method designed for settings like LLM KV cache compression and vector search. Instead of only trying to reconstruct vectors with low MSE, it explicitly cares about preserving the inner products that downstream systems rely on. It does this with a two-stage design: a strong first approximation for the main vector, followed by a 1-bit QJL correction on the residual to reduce inner-product bias. That combination is what makes TurboQuant different from naive low-bit quantization.
Super Short Recap
If you only want the essentials, remember these seven lines:
- attention depends on
- naive quantization can distort that score
- low MSE alone is not enough
- TurboQuant first makes a strong compressed approximation
- then it uses 1-bit QJL on the residual
- this improves inner-product preservation
- that is why TurboQuant is useful for KV cache compression and vector search
What to Read Next
If you want to go one step deeper after this article, the best next topics are:
- KV cache internals in Transformers
- Why attention logits are sensitive to quantization error
- What QJL is doing mathematically
- How the paper’s lower-bound argument works
That sequence will take you from intuition into real paper-level understanding.
References
- Google Research Blog, TurboQuant: Redefining AI efficiency with extreme compression
<https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/>
- Zandieh, Daliri, Hadian, Mirrokni, TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
<https://arxiv.org/abs/2504.19874>