Public note
Quantization for LLMs: The Practical Compression Idea You Need Before Understanding TurboQuant
This note explains quantization in the context of large language models (LLMs), focusing on its role in reducing memory usage and bandwidth by storing numbers with fewer bits, while preserving critical vector interactions for attention mechanisms.
Meta description: Learn what quantization means in machine learning, how low-bit compression works in LLMs, and why quantization error matters for attention, KV cache, and TurboQuant.
Why Read This After the Inner Product Article?
In the previous article, we built one key idea:
LLMs often care less about preserving exact vector values and more about preserving the relationships between vectors, especially inner products.
Now we can ask the next question:
If exact values are not always necessary, how can we store vectors more cheaply?
The most important answer is quantization.
Quantization is one of the central ideas behind efficient LLM inference. It is used to reduce memory usage, bandwidth, and sometimes latency by storing numbers with fewer bits. But quantization is not just a storage trick. In LLMs, it changes how the model sees weights, activations, and especially the KV cache.
This article explains quantization at a practical level for someone with a CS or IT background and basic familiarity with LLMs. The goal is to prepare you for the next step: understanding why TurboQuant is not just another low-bit compression method, but a method designed around preserving the right structure.
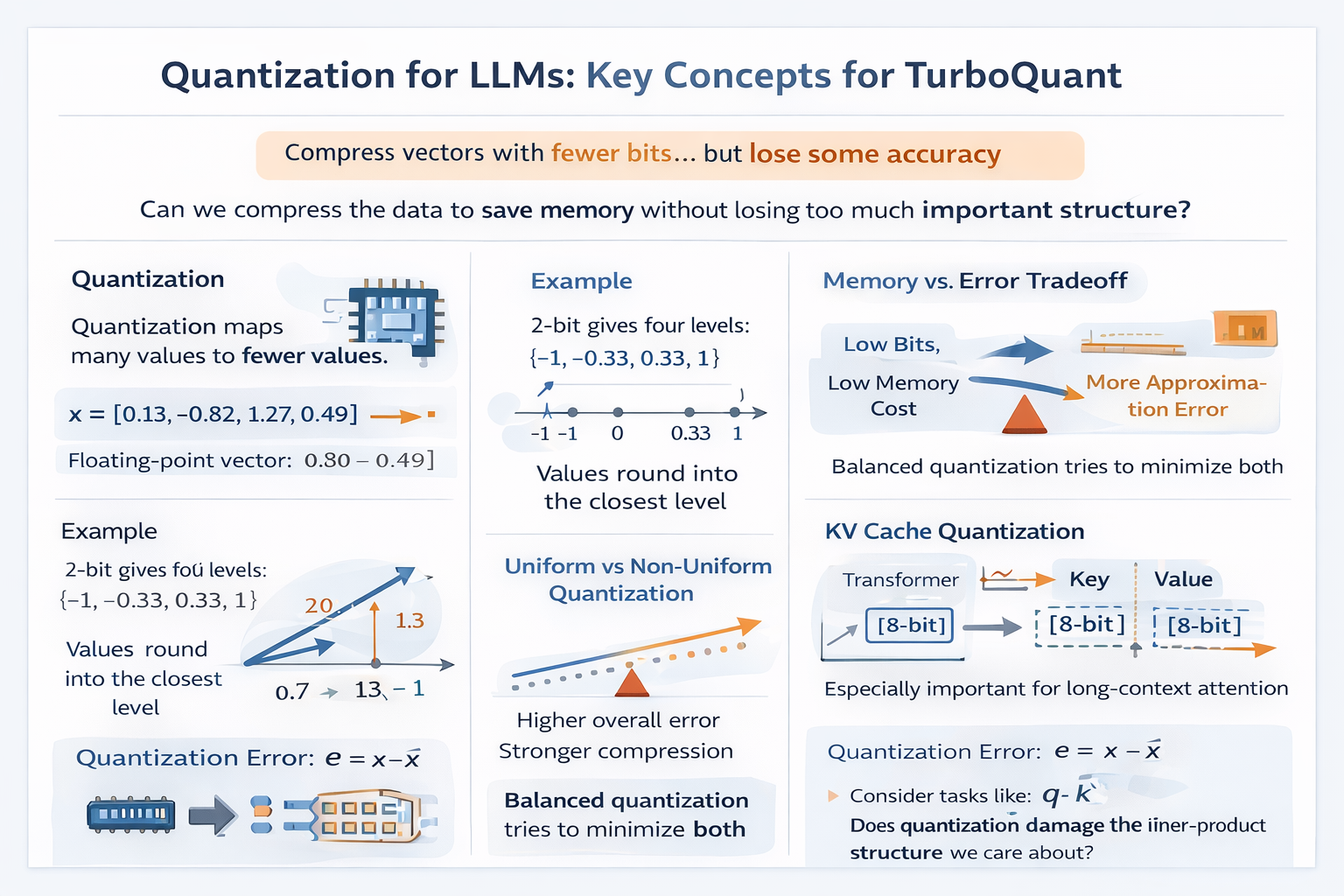
What Is Quantization?
Quantization means mapping a large set of possible numeric values into a smaller set of representative values.
Suppose a vector contains floating-point values like this:
A coarse quantized version might be:
This saves memory because the quantized values can often be stored with fewer bits.
The core tradeoff is simple:
- fewer bits means lower memory cost
- fewer bits also means more approximation error
So quantization is always a compromise between efficiency and accuracy.
Why Quantization Matters in LLMs
LLMs are huge, and inference is expensive.
Even when the model weights fit on a GPU, other parts of inference can still become bottlenecks:
- model weights
- activations
- optimizer states during training
- the KV cache during long-context inference
For serving and deployment, the KV cache is especially important. As sequence length grows, the model stores more keys and values from previous tokens, and memory usage grows quickly.
That leads to a practical engineering question:
Can we store all of this information with fewer bits while keeping model quality high?
Quantization is one of the main answers.
Floating-Point vs Low-Bit Representation
Normally, model values are stored in formats like:
- FP32
- FP16
- BF16
These preserve a wide range of values with fairly high precision.
Quantization replaces them with lower-bit formats such as:
- 8-bit
- 4-bit
- 2-bit
- sometimes even 1-bit
A simple way to think about bit width is:
- 16-bit gives many more possible values than 4-bit
- 4-bit gives many more possible values than 2-bit
- 1-bit is extremely restrictive
In general, if you use bits, you can represent at most:
distinct levels.
So:
- 8-bit gives levels
- 4-bit gives levels
- 2-bit gives levels
- 1-bit gives levels
Fewer levels means stronger compression, but also more distortion.
The Simplest Intuition: Rounding to Buckets
The easiest way to understand quantization is to think of it as rounding into buckets.
Imagine values between and .
If we use 2-bit quantization, we only have 4 levels. For example, we might allow only:
Now consider a few original values:
- becomes
- becomes
- becomes or , depending on the rule
So quantization takes a continuous range and forces it into a small number of allowed outputs.
That is all quantization really is.
A Basic Mathematical View
A common quantization pipeline looks like this:
- scale the value into a discrete integer range
- round it
- store the low-bit integer
- optionally dequantize it later for computation
A very common formula is:
where:
- is the original value
- is a scale factor
- is the quantized integer
To reconstruct an approximate value, we use:
This is a simplified picture, but it captures the main idea.
The scale factor tells us how much real value each integer step represents.
Why Do We Need a Scale?
Suppose you want to store values with 4 bits.
That gives only 16 possible integer levels. If you do not use a scale, those levels may be too small or too large for the actual data.
For example, if your real values are mostly between and , the scale should be different from a case where the values range from to .
The scale connects the low-bit grid to the real range of the tensor.
Without a good scale, quantization becomes much worse.
Symmetric vs Asymmetric Quantization
Two common styles are symmetric and asymmetric quantization.
Symmetric quantization
The representable values are centered around zero.
A simplified form is:
and then:
This is common when values are roughly balanced around zero.
Asymmetric quantization
The range is shifted using a zero-point.
A simplified form is:
and reconstruction becomes:
where is the zero-point.
This helps when the data is not naturally centered around zero.
In practice, many efficient LLM quantization systems prefer simpler schemes when possible, because every extra parameter adds overhead.
The Hidden Cost: Quantization Metadata
This point matters a lot later for TurboQuant.
When people say something like "4-bit quantization," it sounds as if every value costs exactly 4 bits. But in practice, quantization often also needs extra metadata such as:
- scale values
- zero-points
- group statistics
- calibration information
That means the effective cost per stored number may be higher than the advertised bit width.
For example, a scheme may be called 2-bit, but once you include per-group scale and offset data, the true average memory cost becomes larger.
This hidden overhead is one reason extreme compression is harder than it first appears.
Uniform vs Non-Uniform Quantization
Another important distinction is how the allowed levels are spaced.
Uniform quantization
The levels are evenly spaced.
Example:
This is simple and hardware-friendly.
Non-uniform quantization
The levels are not evenly spaced. More levels may be placed where the data is dense.
This can reduce error if the tensor distribution is not uniform.
In practice, the right choice depends on the data distribution and the cost of implementing the scheme.
What Exactly Gets Quantized in an LLM?
When people talk about quantizing an LLM, they may mean different things.
1. Weight quantization
The model weights are stored in fewer bits.
This is the most common and easiest to explain. It mainly reduces the memory footprint of the model itself.
2. Activation quantization
Intermediate values computed during the forward pass are quantized.
This can improve efficiency, but is often trickier because activations change with each input.
3. KV cache quantization
The stored keys and values from previous tokens are quantized.
This is especially useful for long-context inference, because the KV cache can become a major memory bottleneck.
TurboQuant is most interesting in this third setting.
Why KV Cache Quantization Is Special
Weights are static. You quantize them once and reuse them.
The KV cache is different:
- it grows during inference
- it depends on the prompt and generated tokens
- it directly affects attention
- errors can accumulate over long contexts
This makes KV cache quantization more delicate than simple weight compression.
In particular, if the quantized keys no longer preserve the right inner products with the query vectors, attention quality can degrade.
That is why the connection between inner product and quantization is so important.
Quantization Error: What Is Actually Lost?
Quantization introduces error because the reconstructed value is not identical to the original value .
The simplest error term is:
If you do this element by element for a whole tensor, you get a distorted version of the original vector.
The basic compression question becomes:
How harmful is that distortion?
There is no single answer. It depends on what the model does with the tensor afterward.
If the next computation depends mostly on exact element values, then plain reconstruction error matters a lot.
If the next computation depends more on inner products, distances, or ranking, then structure-preserving error matters more.
That is exactly the viewpoint that becomes important for TurboQuant.
MSE: The Most Common Error Metric
A very common way to measure quantization quality is mean squared error (MSE):
This asks:
On average, how far are the reconstructed values from the originals?
MSE is useful because it is simple and mathematically convenient.
But in LLMs, it is not always the full story.
A quantized tensor can have acceptable MSE and still damage the computation that actually matters, especially if it distorts attention scores.
Why Good MSE Does Not Guarantee Good Attention
Attention uses operations like:
So what the model really sees is not just the quantized key vector itself, but the interaction between the query and the key.
A quantized key may be close in ordinary numeric terms, yet still shift the inner product enough to change token ranking.
That is why a more LLM-aware question is:
Does the quantized representation preserve the attention-relevant structure?
This is one of the core reasons why TurboQuant is conceptually different from methods that optimize only for standard reconstruction quality.
Per-Tensor, Per-Channel, and Group-Wise Quantization
Another important design choice is how widely a single scale is shared.
Per-tensor quantization
One scale for the whole tensor.
This is simple, but often too coarse.
Per-channel quantization
A separate scale for each channel or feature dimension.
This usually improves quality because different channels can have different ranges.
Group-wise or block-wise quantization
A scale is shared within small groups of values.
This is a common compromise between quality and storage cost.
But notice the tradeoff:
- more local scales often improve accuracy
- more local scales also increase metadata overhead
Again, this becomes relevant when we later think about why certain extreme compression methods try to avoid too much side information.
Calibration: Why Real Data Matters
Some quantization methods need calibration, meaning they examine sample data to estimate ranges, scales, or clipping thresholds.
This can help because real model distributions are not always well behaved.
But calibration also makes the method less simple:
- it adds preprocessing
- it may depend on the calibration dataset
- it can be less robust across settings
Methods that work with little or no calibration can be very attractive operationally.
This is another practical reason some newer quantization approaches stand out.
Dequantization: Are We Still Computing in Float?
Often, yes.
Many practical systems do not perform every operation directly in ultra-low-bit arithmetic. Instead they:
- store values in compressed low-bit form
- partially reconstruct them during use
- compute critical operations in higher precision
So quantization can reduce storage and bandwidth even if some computation still happens in FP16 or BF16.
This matters because compression benefits can come not only from faster arithmetic, but also from moving less data.
For long-context inference, memory movement is often just as important as raw compute.
Why 4-Bit Feels Reasonable but 2-Bit Feels Dangerous
As bit width gets lower, two things happen at once:
- the number of representable levels drops quickly
- the error becomes harder to control
Going from 16-bit to 8-bit often feels manageable.
Going from 8-bit to 4-bit is much more aggressive, but still practical in many settings.
Going from 4-bit to 2-bit is a big jump.
Going to 1-bit is extreme.
At those very low bit widths, naive schemes can distort the data so much that standard reconstruction-based reasoning starts to break down. That is why more specialized ideas are needed.
TurboQuant lives in this extreme-compression regime.
A Useful Mental Model: Quantization Is Controlled Damage
A good way to think about quantization is this:
Quantization is deliberate, structured damage to a tensor.
You accept some loss because perfect storage is too expensive.
The engineering challenge is not avoiding damage completely. That is impossible.
The challenge is:
Can we damage the tensor in a way that does not break the downstream computation we care about?
For basic compression, that may mean preserving raw values reasonably well.
For attention-heavy systems, it may mean preserving inner products.
For retrieval systems, it may mean preserving ranking and distance relationships.
This is exactly the bridge to TurboQuant.
The Conceptual Link to TurboQuant
By now, we have enough to state the key transition clearly.
Standard quantization thinking often sounds like this:
Make the reconstructed vector close to the original vector.
TurboQuant-style thinking asks a more task-aware question:
Make the compressed representation preserve the important inner products and structure used by attention and retrieval.
That is why understanding quantization alone is not enough. You also need the inner-product perspective from the previous article.
Together, these two ideas set up the main problem TurboQuant is trying to solve:
How can we compress vectors extremely aggressively while preserving the interactions that matter most?
Quick Recap
Here is the shortest summary of quantization in the LLM setting:
- quantization maps many real values into fewer low-bit levels
- this reduces memory and bandwidth
- it introduces approximation error
- scales and zero-points help map real values into integer grids
- per-group metadata can add hidden overhead
- weights, activations, and KV cache can all be quantized
- KV cache quantization is especially sensitive because it directly affects attention
- low MSE is useful, but not always enough
- in LLMs, preserving inner-product structure can matter more than preserving exact values
What to Read Next Before TurboQuant
Once this article feels clear, the next concepts to study are:
- What the KV cache stores in a Transformer
- Why long-context inference makes KV cache memory expensive
- Why naive low-bit quantization can distort attention scores
- How TurboQuant combines compression with inner-product preservation
That sequence will make the research paper much easier to read.
Final Takeaway
If the previous article gave you the question:
Why does inner product matter in LLMs?
this article gives you the next one:
If we must compress vectors, what kind of approximation is acceptable?
Quantization is the standard answer to that compression problem.
But once you look closely at attention, it becomes clear that not all quantization error is equally bad.
That insight is the doorway to understanding why TurboQuant is interesting.