Public note
Inner Product for LLMs: The Simple Math You Need Before Understanding TurboQuant
This note explains the concept of inner product in large language models (LLMs), emphasizing its importance for attention mechanisms and vector interactions, before delving into TurboQuant's approach to extreme compression while preserving crucial inner-product relationships.
Meta description: A beginner-friendly guide to inner product in LLMs, attention, and quantization. Learn the key math concept you need before reading TurboQuant.
Why Read This Before TurboQuant?
If you want to understand TurboQuant, you should first understand one core idea:
Large language models do not just care about storing vectors accurately. They care about preserving the right relationships between vectors.
One of the most important relationships is the inner product.
That may sound like pure linear algebra, but the intuition is simple. In an LLM, many decisions depend on whether two vectors match well. The inner product is one of the main ways that match is measured.
This article explains inner product at a level that should feel comfortable for someone with an IT or computer science background and basic familiarity with LLMs. The goal is to give you the mental model you need before reading TurboQuant.
What Is a Vector in an LLM?
In machine learning, a vector is just an ordered list of numbers.
For example:
In an LLM, vectors can represent many things:
- token embeddings
- hidden states
- query vectors
- key vectors
- value vectors
So when we talk about the inner product, we are really asking:
How do we compare two vectors in a way that matters for model behavior?
What Is an Inner Product?
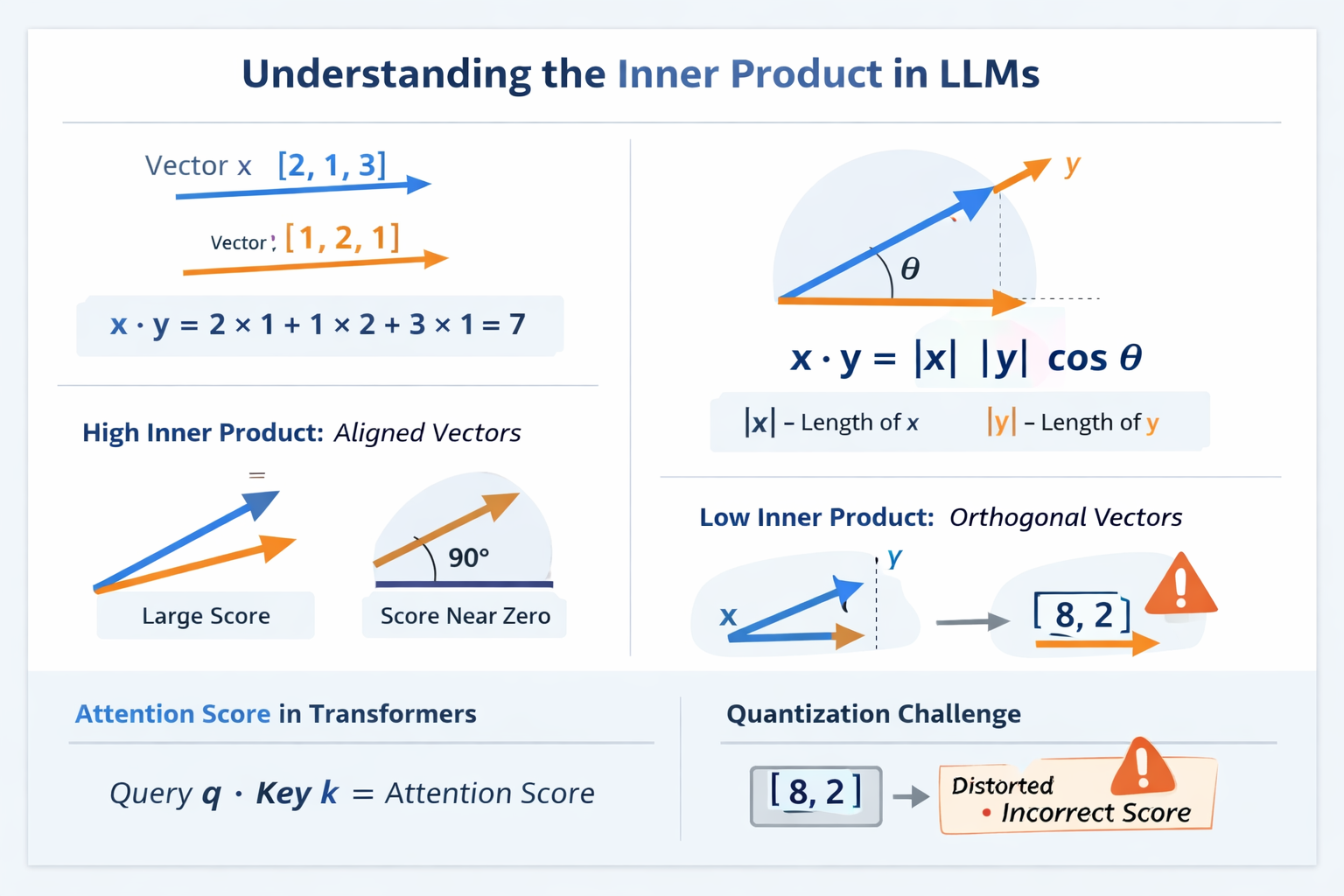
The inner product of two vectors is computed by multiplying matching components and then summing the results.
If
then
That is the mechanical definition.
The useful interpretation is this:
The inner product measures how well two vectors align.
If two vectors point in similar directions, their inner product tends to be large. If they are unrelated or orthogonal, it tends to be small. If they point in opposite directions, it can become negative.
Why Does Inner Product Represent Alignment?
The geometric form of the inner product is:
where:
- is the length of vector
- is the length of vector
- is the angle between them
This gives the main intuition:
- if the angle is small, is large, so the inner product is large
- if the angle is , then , so the inner product is
- if the angle is close to , then is negative, so the inner product is negative
So inner product is not just a formula. It is a way to measure directional similarity with magnitude included.
A Simple Example with Angles
Take these two vectors:
Their inner product is:
These vectors are at to each other, so they are orthogonal.
Now compare that with:
Then:
They point in the same direction, so the inner product is large relative to their sizes.
This is the core idea:
The inner product increases when vectors point in similar directions.
Inner Product vs Cosine Similarity
People often confuse inner product and cosine similarity because they are closely related.
Inner product
This depends on both direction and magnitude.
Cosine similarity
This measures direction only. It removes the effect of vector length.
So:
- inner product asks: how strongly do these vectors interact?
- cosine similarity asks: how similar are their directions, ignoring scale?
This distinction matters because LLM attention uses inner products directly.
Why Inner Product Matters in Transformers
This is the key connection to LLMs.
In self-attention, the model computes a score between a query vector and a key vector. At a simplified level, the score comes from:
where:
- is the query vector for the current token
- is the key vector for a previous token
This score tells the model how much the current token should pay attention to that earlier token.
A higher inner product usually means:
This past token is more relevant right now.
A lower inner product usually means:
This token matters less.
So attention patterns depend directly on inner products.
A Small Attention Example
Suppose the current token produces this query:
Two previous tokens have keys:
Now compute the scores.
For token A:
For token B:
So token A gets a much higher relevance score than token B.
That means the model will focus more on token A.
This is exactly why preserving inner products matters. If compression changes these scores too much, the model may attend to the wrong tokens.
Why This Matters More Than Accurate Numbers
A common first assumption is:
Compression should preserve the original vector values as accurately as possible.
That sounds reasonable, but for LLMs it is not the full story.
What matters is not just whether each numeric component is reconstructed closely. What matters is whether the model still computes the right relationships between vectors.
A compressed vector can have small-looking numeric error and still distort the inner product in a harmful way.
For example, suppose the original vector is:
and after compression it becomes:
At first glance, that may look acceptable. But now consider this query:
Then:
But:
The original vector had no relevance to this query. The compressed vector suddenly looks relevant.
So the error is not just a little numeric difference. It changes the interaction that the model uses.
What Is Quantization?
Now we can connect inner product to quantization.
Quantization means storing values with fewer bits by mapping many possible real numbers into a smaller set of representative values.
For example, suppose you have:
A coarse quantized version might be:
This saves memory, but introduces error.
In machine learning systems, quantization is useful because it can reduce:
- memory usage
- bandwidth cost
- latency
- hardware pressure during inference
This becomes especially important in LLMs with long contexts, where the KV cache becomes very large.
Why Quantization Is Hard in LLMs
Quantization always creates some information loss.
So the real question is:
Which information must be preserved, and which information can be approximated?
A naive answer is:
Preserve the raw vector values as closely as possible.
A more LLM-aware answer is:
Preserve the inner products that drive attention and retrieval.
This is the conceptual bridge to TurboQuant.
TurboQuant is interesting because it is based on the idea that in tasks like attention and vector search, preserving inner-product structure can matter more than minimizing ordinary reconstruction error alone.
MSE Is Useful, but Not the Whole Story
A common way to judge quantization is with mean squared error (MSE):
This tells us how close the compressed vector is to the original vector, component by component.
That is useful. But it is not always enough.
Why?
Because LLM attention does not directly use MSE. It uses expressions like:
So even if a quantized vector has low MSE, it may still distort the inner products that attention depends on.
This is one of the most important mindset shifts for understanding LLM compression research.
A Better Mental Model for LLM Compression
A good way to think about it is this:
- MSE asks: Did I reconstruct the vector values closely?
- Inner-product preservation asks: Did I preserve the relationships the model actually uses?
For attention, the second question is often more important.
For retrieval, it is also often more important.
That is why TurboQuant is not just about making vectors smaller. It is about compressing them without breaking the structure that downstream computations depend on.
Where KV Cache Fits Into This
If you have worked with LLM inference, you may already know that the KV cache stores keys and values from previous tokens so the model does not recompute everything from scratch.
That cache grows with:
- number of layers
- number of attention heads
- sequence length
- hidden dimension
So long-context inference can become memory-heavy very quickly.
This leads to a practical engineering problem:
How do we store the KV cache much more cheaply without destroying attention quality?
That leads directly to the research question behind TurboQuant:
Can we compress vectors very aggressively while still preserving the inner products that matter for attention?
The One Big Idea You Should Carry Into TurboQuant
Before reading TurboQuant, remember this sentence:
For many LLM computations, preserving vector values exactly is less important than preserving the inner products they induce.
That is the main conceptual lens.
If you keep that in mind, TurboQuant stops looking like just another quantization paper and starts looking like a more targeted answer to a more important question.
Not:
How do we make vectors smaller?
But:
How do we make vectors smaller while preserving the signal that attention actually uses?
Quick Recap
Here is the shortest possible summary:
- vectors are everywhere in LLMs
- the inner product measures how well two vectors align
- attention scores depend directly on inner products between queries and keys
- quantization reduces memory by storing vectors with fewer bits
- low reconstruction error alone is not enough
- what really matters is whether important inner products stay stable
- this idea is a core stepping stone toward understanding TurboQuant
What to Read Next Before TurboQuant
Once this intuition feels natural, the next concepts to study are:
- what the KV cache is
- why KV cache memory becomes a bottleneck
- why standard quantization can distort attention
- how TurboQuant tries to preserve inner-product structure under extreme compression
That sequence makes the research much easier to follow.
Final Takeaway
If you only remember one thing from this article, make it this:
In LLM systems, the meaning of a vector often lives in how it interacts with other vectors.
And those interactions are often measured by the inner product.
That is why inner product is not just a piece of linear algebra. It is one of the core ideas behind how attention works, why compression is difficult, and why TurboQuant is worth studying.