Public note
Supermemory: Why This AI Memory Project Matters Beyond Developers
Supermemory is an open-source project aiming to provide persistent memory and context for AI systems, addressing the issue of forgetfulness in current assistants by combining user profiles, search capabilities, and file processing into a cohesive system.
Summary
Supermemory is an open-source project that tries to solve one of the biggest problems in modern AI: most assistants forget too much. The project presents itself as a memory and context layer for AI, combining persistent memory, user profiles, search, connectors, and file processing into one system.
For people interested in IT but not necessarily developers, the easiest way to understand Supermemory is this:
It is infrastructure that helps AI tools remember useful information over time, instead of starting from zero in every conversation.
That matters because better memory makes AI more personal, more consistent, and often more useful in the real world.
What the Project Is
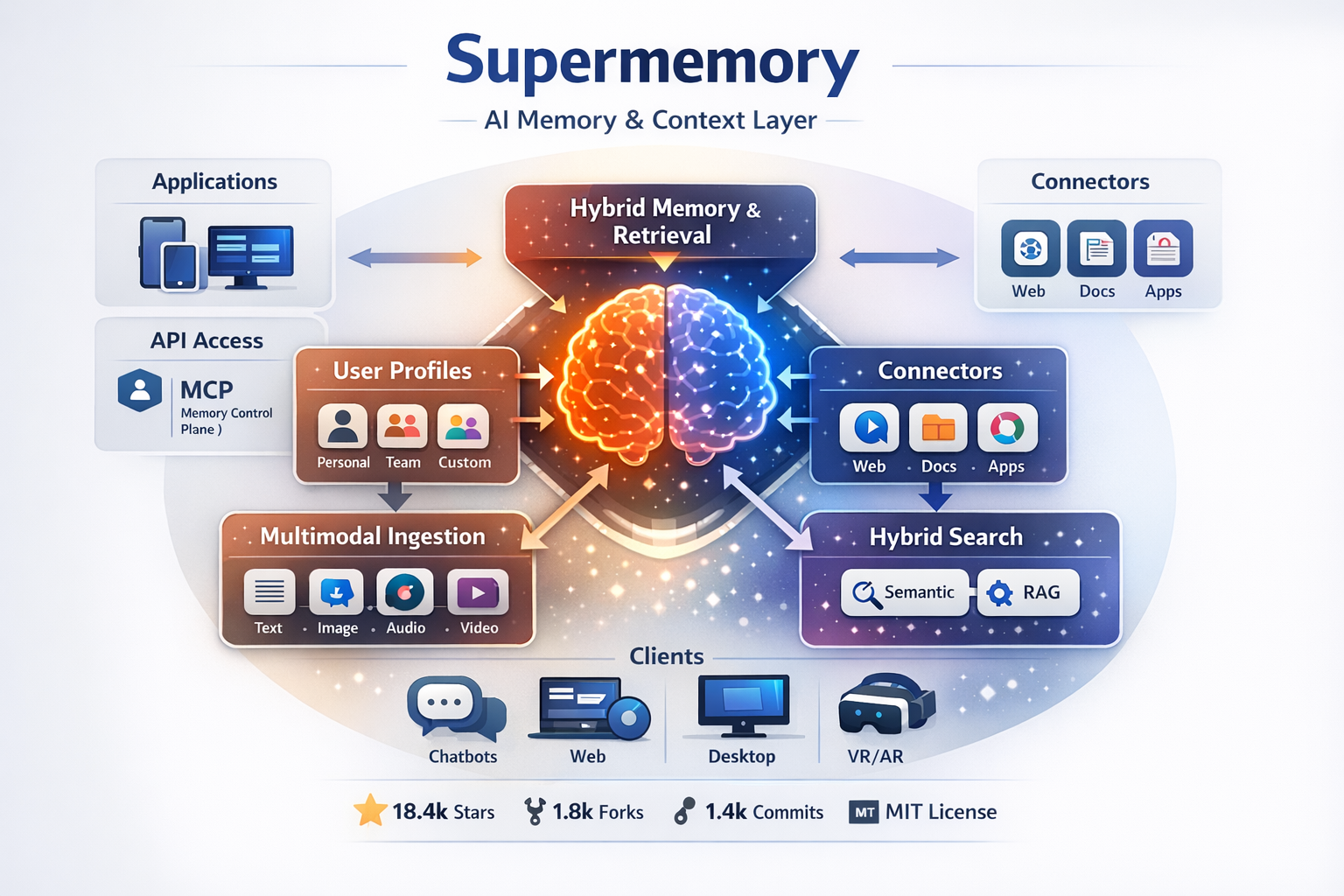
The GitHub repository describes Supermemory as a “memory engine and app” and “the memory API for the AI era.” It is not just a developer SDK. It includes:
- a consumer-facing app
- an API for products and agents
- an MCP server for AI tools
- plugins for coding assistants
- connectors for syncing external information
This broad scope is one reason the project has attracted significant attention. At the time of writing, the repository shows about 18.4k stars, 1.8k forks, 1,473 commits, and an MIT license.
From an IT trend perspective, that is important. Supermemory is not a toy demo. It looks like a serious attempt to become a reusable memory layer for AI systems.
Why Supermemory Is Interesting
Most people have already noticed the basic limitation of AI assistants:
- they lose context between conversations
- they forget personal preferences
- they repeat questions
- they do not always distinguish temporary facts from lasting ones
Supermemory is built to address exactly that. According to the repository and official documentation, the system can:
- extract facts from conversations
- build and maintain user profiles
- combine memory with RAG-style search
- sync external data sources
- process files such as PDFs, images, videos, and code
In plain English, this means the system is trying to become the “memory brain” behind an AI assistant.
That is good news for normal IT readers because it shows where AI products are heading. The next generation of AI will not just answer prompts. It will remember relationships, preferences, projects, and evolving context.
How It Works in Simple Terms
A beginner-friendly way to think about Supermemory is as a pipeline with a few layers:
1. It receives information
Supermemory can ingest:
- conversations
- documents
- files
- synced content from tools like Google Drive, Gmail, Notion, OneDrive, GitHub, and the web
2. It extracts useful facts
Instead of treating everything as raw text forever, it tries to identify what matters, such as:
- stable facts
- recent activity
- changing information
- contradictions
- temporary facts that should expire later
3. It builds a user profile
The official docs describe a profile made of:
- static context: long-term facts the system should usually know
- dynamic context: more recent or temporary activity
This matters because it turns memory from a pile of notes into a structured understanding of a person or project.
4. It retrieves the right context later
When the AI needs context, Supermemory can return:
- relevant memories
- the user profile
- related knowledge-base documents
The project calls this hybrid search, meaning it can mix personal memory and traditional document retrieval in one system.
What Makes It Different
One of the strongest ideas behind Supermemory is that it does not frame memory as simple chat history.
The official docs explicitly distinguish memory from RAG:
- RAG is about retrieving document chunks
- memory is about tracking evolving user facts over time
That difference is easy to miss, but it matters a lot.
For example, a normal search system might find that a user once said they lived in New York. A true memory system should understand that if the user later says they moved to San Francisco, the newer fact should replace the old one. Supermemory says it handles temporal changes, contradictions, and automatic forgetting.
That makes the project more ambitious than a simple search layer.
Key Features
1. Persistent memory for AI
Supermemory stores useful context across sessions so AI tools can feel less stateless.
Why it matters:
This is one of the biggest gaps in everyday AI use today.
2. User profiles
The system automatically maintains a profile with static and dynamic context.
Why it matters:
It gives AI a faster way to understand a person without asking the same things repeatedly.
3. Hybrid search
It combines memory and RAG in one query path.
Why it matters:
That makes it easier to blend personal context with documents and knowledge bases.
4. Connectors
The official repo lists connectors for Google Drive, Gmail, Notion, OneDrive, GitHub, and a web crawler.
Why it matters:
AI memory becomes much more useful when it can pull from the tools people already use.
5. Multi-modal extraction
The project says it supports PDFs, images, videos, and code.
Why it matters:
Modern AI systems increasingly work across formats, not just text.
6. Consumer app + developer platform
Supermemory is not only for product teams. The official site says there is a free consumer-facing app and also an API for builders.
Why it matters:
This gives the project a broader audience than many infrastructure tools.
7. MCP support and plugins
The repository describes an MCP server plus plugins for Claude Code, OpenCode, and OpenClaw, and support for clients such as Claude Desktop, Cursor, Windsurf, VS Code, Claude Code, OpenCode, and OpenClaw.
Why it matters:
It suggests Supermemory wants to be a cross-tool memory layer, not a feature locked inside one app.
Why This Matters for People Interested in IT
Even if you never write code, Supermemory is still interesting because it represents a bigger shift in technology.
AI is moving from answers to continuity
The value of AI is no longer just producing a response. More and more, the value is in remembering what matters across time.
Personalization is becoming infrastructure
Instead of manually pasting past context into every new conversation, systems like Supermemory try to make personalization automatic.
The browser and productivity stack are becoming “memory-aware”
When AI can connect to email, documents, code, notes, and conversations, it starts acting less like a chatbot and more like a persistent digital assistant.
Open-source AI infrastructure is maturing
Supermemory is MIT-licensed and has already gained strong public traction. That makes it part of the broader story of open-source infrastructure becoming more capable and more production-oriented.
Benchmarks and Credibility
Supermemory makes strong performance claims. The repository says it is #1 on LongMemEval, LoCoMo, and ConvoMem, which it describes as major AI memory benchmarks. The docs also mention an open-source evaluation framework called MemoryBench for comparing memory providers.
The important point for ordinary readers is not the benchmark names themselves. It is that AI memory is becoming a measurable engineering category, not just a vague idea.
That said, these are still claims presented by the project and should be read with the usual healthy caution. Benchmarks are useful, but real-world usefulness still depends on product fit, reliability, privacy, and integration quality.
Strengths
- Clear value proposition: fixing AI forgetfulness
- Covers both consumer and developer use cases
- Broad connector support
- Works across multiple AI clients and workflows
- Strong open-source momentum and community interest
- Thinks beyond simple vector search into actual memory behavior
Caveats
- The project is ambitious, which means expectations should stay realistic
- Memory systems are harder to judge than simple chat apps because quality depends on context accuracy
- Privacy, retention, and sync behavior matter a lot when personal or company data is involved
- A strong benchmark result does not automatically guarantee the best experience for every use case
In other words, Supermemory is promising, but like many fast-moving AI infrastructure projects, its long-term importance will depend on execution as much as vision.
Why the Project Is Good News
The good news about Supermemory is not just that it has thousands of GitHub stars. The real good news is that it tackles a problem many people already feel: AI can be impressive, but it is often forgetful and fragmented.
Supermemory points toward a better model where AI systems can:
- remember what matters
- adapt to changing facts
- combine personal context with documents
- work across tools instead of staying trapped in one app
For everyday people interested in IT, that is one of the most important trends to watch. Memory is becoming part of the core stack of AI, and projects like Supermemory show what that future may look like.
Conclusion
Supermemory is one of the more interesting open-source AI infrastructure projects right now because it focuses on continuity, not just generation.
If you explain it in the simplest possible way, it is this:
Supermemory helps AI remember you, your work, and your information more intelligently over time.
That makes it relevant not only to developers, but to anyone trying to understand where AI products are going next.
A few years ago, the big question was whether AI could answer questions well. Now the bigger question is whether AI can remember enough to be genuinely useful.
Supermemory is built around that second question, which is exactly why it is worth paying attention to.