Public note
LLM Wiki: From One Idea File to a New Class of Persistent AI Knowledge Systems
Subheadline
Andrej Karpathy’s LLM Wiki note proposes a shift away from query-time RAG toward an LLM-maintained, ever-evolving markdown wiki. In the days since publication, the concept has already started turning into installable agent skills, scaffolds, and lightweight tooling.
Lead
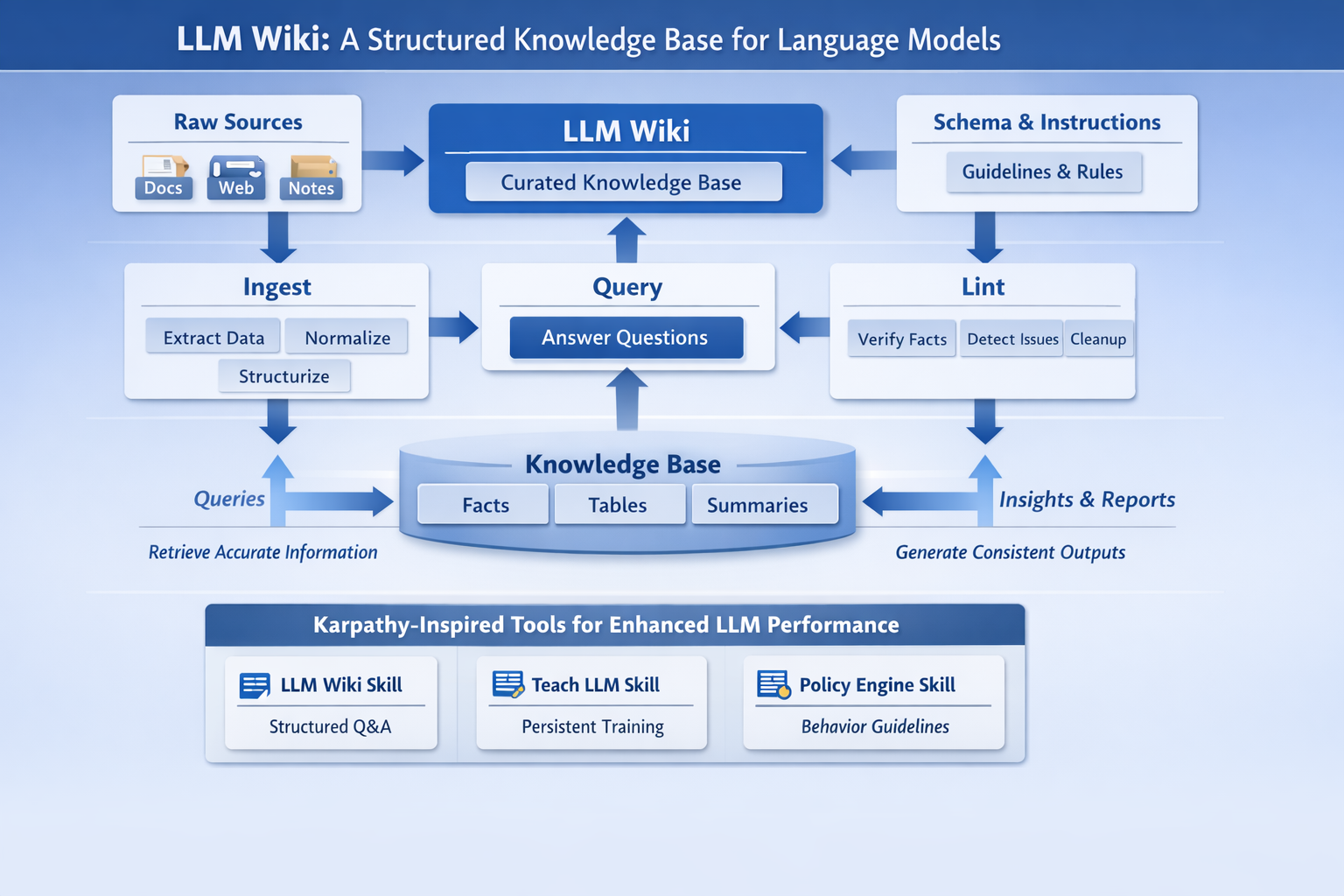
Most document-based AI systems still behave like very smart search boxes. You upload files, ask a question, and the model hunts through chunks of text to reconstruct an answer on demand. Andrej Karpathy’s LLM Wiki argues for something more durable: instead of rediscovering knowledge from scratch every time, let the model continuously compile what it reads into a persistent, cross-linked wiki that grows smarter as new material arrives.
That shift sounds subtle, but it changes the role of the large language model. In Karpathy’s framing, the model is no longer just a retrieval layer sitting on top of a pile of documents. It becomes an active maintainer of a knowledge base — summarizing sources, updating concept pages, linking related topics, tracking contradictions, and preserving useful analyses that would otherwise disappear into chat logs.
The idea has resonated quickly because it taps into a familiar frustration. Traditional RAG is good at finding fragments, but it often struggles to accumulate judgment. LLM Wiki is pitched as a way to turn raw reading into a compounding artifact: a markdown-based “second brain” that can be queried, audited, and improved over time.
At a Glance
- Core thesis: Karpathy’s LLM Wiki replaces one-off retrieval with a persistent, LLM-maintained markdown wiki.
- Three-layer design: raw sources, the generated wiki, and a schema/instruction file that governs maintenance.
- Workflow: ingest new documents, query the wiki, and periodically lint it for contradictions, orphan pages, and missing links.
- Key differentiator: useful answers can be written back into the wiki, so research compounds instead of vanishing in chat history.
- Ecosystem trend: early community projects are already packaging the pattern into reusable agent skills and CLI scaffolds.
- Reality check: the repository the user shared,
forrestchang/andrej-karpathy-skills, is not a dedicated LLM Wiki implementation, but it does show how Karpathy-style guidance is being turned into reusable agent behavior.
What Happened
Karpathy published “LLM Wiki” on April 4, 2026 as what he explicitly called an “idea file” — a document designed to be pasted into an LLM agent so the human and model can co-design a working system around it. The proposal is intentionally abstract. It does not ship a product, benchmark, or finished framework. Instead, it outlines a pattern.
The pattern starts with a critique of mainstream document QA: every question forces the model to retrieve raw fragments and synthesize an answer again. That means subtle cross-document understanding has to be rebuilt every time. Karpathy’s answer is to move the synthesis forward in time. The model should read new sources once, fold the findings into an evolving wiki, and preserve the resulting structure for future use.
That has two implications. First, the wiki becomes the primary working memory for the system, sitting between the human and the raw documents. Second, the model’s maintenance labor becomes the product: updating summaries, revising entity pages, checking consistency, and keeping the graph of pages healthy as the corpus grows.
Key Facts / Comparison
| Aspect | Conventional RAG / file chat | LLM Wiki pattern |
|---|---|---|
| Primary interaction | Retrieve chunks at query time | Maintain a persistent markdown wiki |
| Knowledge accumulation | Minimal; answers are re-derived repeatedly | High; answers and syntheses can be saved back |
| Source handling | Documents are indexed for retrieval | Documents are read, summarized, linked, and integrated |
| Structure | Mostly chunk/vector based | Human-readable pages, summaries, entities, concepts, insights |
| Consistency work | Often implicit and ad hoc | Explicit maintenance: updates, contradictions, linting |
| Best interface | Chat window | Chat plus editable markdown workspace such as Obsidian |
| Infrastructure need | Usually embeddings/vector DB | Can start with markdown + index/log; search can be added later |
The three layers Karpathy describes
| Layer | Role | Owner |
|---|---|---|
| Raw sources | Immutable source documents, articles, papers, images, data files | Human-curated |
| Wiki | Interlinked markdown pages, summaries, concepts, entities, syntheses | LLM-maintained |
| Schema | The instructions that define conventions and workflows | Human + LLM together |
Background and Context
The idea lands at a moment when developers are rethinking how AI systems should remember. The past two years have been dominated by retrieval-augmented generation, vector stores, and increasingly large context windows. Those tools help models find information, but they do not automatically create a maintained body of knowledge.
LLM Wiki borrows more from wiki culture than from classic RAG architecture. Karpathy explicitly compares the experience to keeping an LLM agent open beside Obsidian, using the note-taking app as the “IDE,” the model as the “programmer,” and the wiki itself as the “codebase.” It is a telling analogy: the value is not only in the final answers, but in the persistent files, links, and revision history that make later work easier.
The note also evokes Vannevar Bush’s Memex, the long-running dream of a personal, associative knowledge machine. Karpathy’s twist is that LLMs can handle the housekeeping that has historically made personal knowledge systems brittle: filing, cross-referencing, updating, and keeping summaries aligned with new evidence.
Why This Matters
The appeal of LLM Wiki is not that it replaces search. It is that it tries to turn AI assistance into cumulative editorial labor.
That matters for several groups:
- Researchers: a model can continuously turn papers, notes, and reports into a navigable knowledge base instead of a pile of PDFs.
- Knowledge workers: meeting notes, internal docs, and transcripts can be converted into living documentation.
- Personal users: reading notes, journals, travel plans, or course material can be compiled into structured, searchable memory.
- Agent developers: the pattern offers a practical middle ground between brittle prompt memory and expensive full-stack RAG systems.
Just as importantly, the wiki is inspectable. Unlike opaque hidden memory systems, a markdown wiki can be read by humans, versioned in Git, and audited for quality.
Insight and Industry Analysis
The most interesting part of LLM Wiki may be how quickly it has escaped the status of “idea file.” Within days, developers began packaging the pattern into skills, plugins, and scaffolding tools that formalize operations such as initialization, ingestion, querying, updating, and linting.
That is the larger industry signal. Developers increasingly do not want only bigger models; they want repeatable workflows that make models behave like disciplined operators. In that sense, LLM Wiki sits at the intersection of two trends:
- Persistent memory for agents
- Skill-based packaging of agent behavior
This is where the shared forrestchang/andrej-karpathy-skills repository becomes relevant, even though it is not itself an LLM Wiki package. That project distills Karpathy-inspired agent behavior into reusable principles such as Think Before Coding, Simplicity First, Surgical Changes, and Goal-Driven Execution. Those ideas are adjacent rather than identical, but they reveal the same movement: turning high-level advice from prominent AI practitioners into operational software instructions.
Meanwhile, more direct LLM Wiki implementations are appearing. Repositories such as wiki-skills, llm-wiki-skill, and hsuanguo/llm-wiki expose the pattern as discrete commands like init, ingest, query, update, and lint, often coupled with markdown-first directory structures and agent-readable SKILL.md files. In other words, the community is rapidly converting a philosophy into tooling.
Pros and Cons
Pros
- Compounding knowledge: the system gets richer as sources and analyses accumulate.
- Human-readable output: markdown pages are inspectable, editable, and version-controllable.
- Lower infrastructure barrier: small to medium corpora can work without full vector-database stacks.
- Better synthesis over time: cross-references and contradictions can be preserved instead of repeatedly rediscovered.
- Operational flexibility: answers can become new wiki pages, presentations, or comparison notes.
Cons
- Quality depends on maintenance discipline: a bad schema or sloppy ingest process can degrade the whole wiki.
- Risk of silent drift: an LLM may introduce subtle errors that propagate across multiple pages.
- Scaling challenges remain: plain markdown and index files may become unwieldy as corpora grow.
- No canonical implementation yet: the ecosystem is fragmented and still highly experimental.
- Human review is still needed: a wiki that compounds mistakes is worse than one that forgets.
Technical Deep Dive
Karpathy’s original note outlines three main operations: ingest, query, and lint.
Operational flow
| Operation | What the LLM does | Why it matters |
|---|---|---|
| Ingest | Reads a new source, writes a summary, updates related pages, updates index, appends log | Compiles raw information into maintained knowledge |
| Query | Reads relevant wiki pages, synthesizes an answer, optionally files the answer back into the wiki | Makes exploration cumulative |
| Lint | Looks for contradictions, stale claims, orphan pages, missing concepts, broken links, data gaps | Prevents knowledge rot |
Recommended file structure in the pattern
| File / directory | Purpose |
|---|---|
raw/ | Immutable source materials |
wiki/index.md | Catalog of pages and one-line summaries |
wiki/log.md | Append-only operational history |
wiki/overview.md | Evolving top-level synthesis |
| page folders or flat pages | Entities, concepts, summaries, insights |
CLAUDE.md, AGENTS.md, or SCHEMA.md | Rules and conventions for the LLM |
Why the “skill” form matters
Community implementations add a missing layer: operational packaging. Instead of asking users to improvise the entire workflow, a skill can define:
- how to scaffold the wiki
- how to name pages and folders
- when to update
index.mdandlog.md - how to handle ingest versus update
- how to run periodic audits
- how to connect lightweight search tools once the wiki gets large
One frequently mentioned complement is QMD, a local search engine for markdown collections that combines keyword search, vector search, and reranking. That matters because Karpathy’s original pattern intentionally starts simple — often with just an index file — but acknowledges that larger wikis may eventually need stronger retrieval support.
What to Watch Next
- Whether one directory structure or skill format emerges as the de facto standard
- How teams add review workflows so the wiki compounds insight rather than hallucinations
- Whether local markdown search tools become the default retrieval layer for larger wikis
- How quickly note-taking apps like Obsidian become the preferred front end for agent-maintained knowledge bases
- Whether the pattern expands from personal research into enterprise documentation, due diligence, and internal memory systems
Conclusion
LLM Wiki is still closer to a design pattern than to a finished product, but that may be exactly why it is spreading so quickly. It offers a simple, legible promise: stop forcing models to rediscover knowledge from raw files every time, and instead let them maintain a body of work that grows in value as it is used.
In practical terms, that makes LLM Wiki one of the most interesting recent shifts in the AI tooling conversation. It reframes the model from answer engine to editor, librarian, and maintainer. And because the output is a visible markdown wiki rather than an invisible memory layer, it gives users something many AI systems still struggle to provide: a durable artifact they can inspect, shape, and keep.