Public note
Graphify: A Multi-Modal Knowledge Graph Builder for AI Coding Assistants
Graphify is an open-source project that builds multi-modal knowledge graphs from code, documentation, and diagrams for AI coding assistants to understand software projects more comprehensively.
Subheadline
Graphify is an open-source project that turns code, documentation, papers, and diagrams into a queryable knowledge graph so AI coding assistants can understand a software project with more structural and architectural context.
Lead
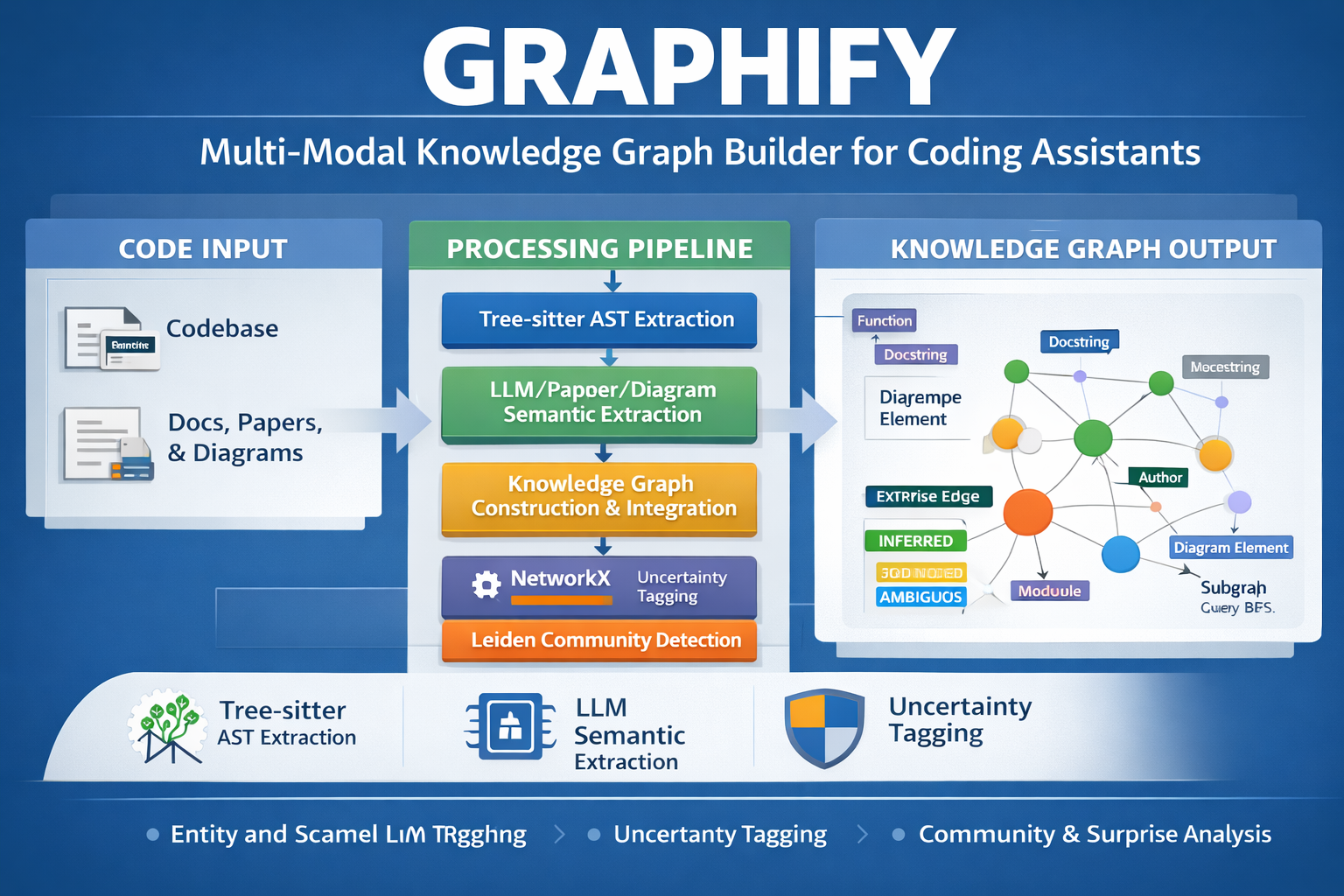
Graphify is not a generic graph-visualization tool. It is a multi-modal knowledge graph builder for software projects, designed to help tools such as Claude Code, OpenAI Codex, and OpenCode understand codebases with more structural and architectural context. According to the official project site, Graphify combines Tree-sitter-based static analysis with LLM-driven semantic extraction to map not just what the code does, but also the design intent expressed in docs, papers, and diagrams.
At a Glance
- Project: Graphify
- Type: Open-source knowledge graph skill for AI coding assistants
- Maintainer: Safi Shamsi
- License: MIT
- Primary purpose: Build a queryable graph from code, docs, papers, and diagrams
- Core stack called out by the project: Tree-sitter, NetworkX, Leiden clustering
- Outputs:
graph.html,graph.json, andGRAPH_REPORT.md
What Happened
Graphify presents itself as an infrastructure layer for code understanding rather than a standalone visualization app. Its pipeline collects project files, extracts structural and semantic signals, merges them into a graph, clusters related concepts into communities, and then exports both machine-readable and human-readable outputs.
On the project site, Graphify says it supports AI coding assistants including Claude Code, OpenAI Codex, and OpenCode. The GitHub repository describes the project more broadly as a skill that can turn folders containing code, docs, papers, images, or videos into a queryable knowledge graph.
Key Facts / Comparison
| Item | What the sources say |
|---|---|
| Identity | Open-source knowledge graph skill for AI coding assistants |
| Input | Code, docs, papers, diagrams, and other project materials |
| Static analysis | Tree-sitter-based AST extraction |
| Graph engine | NetworkX |
| Clustering | Leiden community detection without vector embeddings |
| Main promise | Structural and semantic understanding of codebases |
| Output artifacts | Interactive HTML graph, JSON graph, Markdown report |
Background and Context
Many code-intelligence systems depend heavily on chunking, embedding, and vector retrieval. Graphify argues for a different approach: preserve explicit structure first, then add semantic links on top. In its own documentation, the project positions knowledge graphs as more transparent for code understanding because they can preserve calls, imports, rationale comments, and cross-modal links between source code and external design materials.
That positioning matters because software repositories increasingly include more than source files. Architecture diagrams, technical notes, PDFs, and research papers often carry the rationale behind a system. Graphify is built around the idea that an AI assistant should be able to reason across all of them in one graph.
Why This Matters
The most interesting part of Graphify is that it tries to answer a persistent weakness in code-assistant workflows: source code alone often does not explain architectural intent. Graphify’s pipeline is designed to preserve both structure and meaning.
For teams using AI coding assistants, that can matter in several practical ways:
- It may reduce the need to repeatedly stuff large repositories into context windows.
- It gives assistants an explicit graph of relationships instead of only similarity scores.
- It offers a bridge between implementation details in code and intent captured in supporting documents.
The project site also claims large token reductions when querying graph-derived subgraphs instead of naively sending large corpora to a model.
Insight and Industry Analysis
Graphify sits in a distinct position relative to nearby tool categories.
- It is not a graph database like Neo4j, because its main job is to generate a graph from project artifacts.
- It is not a typical vector-RAG code search tool, because it emphasizes explicit structural edges and graph topology.
- It is not just a visualizer, because the graph is intended to be queried by coding assistants and exported as structured artifacts.
That makes Graphify best understood as a codebase interpretation layer. Its real value is not the picture of the graph itself, but the intermediate representation it builds for downstream assistant workflows.
Strengths, Limitations, and Open Questions
Strengths
- Preserves explicit software structure through AST parsing
- Incorporates docs, papers, and diagrams into the same graph
- Uses transparent graph edges and community structure instead of relying only on embeddings
- Produces multiple outputs for inspection, querying, and reporting
Limitations
- The official materials emphasize the architecture and workflow, but do not provide exhaustive benchmark coverage across many repositories
- Accuracy of semantic extraction still depends on model quality for non-code materials
- Some claims, such as token-efficiency gains, are demonstrated with project examples rather than independent third-party evaluation
Open Questions
- How consistently does the semantic layer perform across very large enterprise repositories?
- How much manual review is needed when inferred cross-modal links are ambiguous?
- How stable are community assignments when repositories evolve rapidly?
Technical Deep Dive
1. Deterministic Tree-sitter AST pass
Graphify’s first pass is a deterministic Tree-sitter walk over every code file it finds. The project’s Tree-sitter documentation explicitly says this stage uses no LLM, no embeddings, and no network calls. Instead, it converts AST information directly into graph nodes and edges.
From that AST pass, Graphify extracts:
- Structural nodes such as classes, functions, methods, modules, traits/interfaces, and top-level variables
- Call-graph edges, where resolved call sites become
callsedges - Import edges, which help connect modules that belong together
- Rationale nodes, where docstrings and specially marked comments such as
NOTE,IMPORTANT,HACK, andWHYare lifted into separate nodes
This is a notable design choice. Graphify is not only mapping software structure, but also trying to preserve why the code was written a certain way when that rationale appears in comments or docstrings.
2. Semantic extraction for non-code materials
The second major layer is semantic extraction over materials such as docs, papers, and diagrams. On its homepage, Graphify says LLMs extract concepts from prose and vision models read diagrams. These semantic outputs are then merged into the same graph as the deterministic code structure.
The Tree-sitter documentation also describes a source-tracking model for graph edges:
EXTRACTEDfor deterministic facts from code, with confidence1.0INFERREDfor model-derived linksAMBIGUOUSfor cases where the model is uncertain
That separation is important because it gives reviewers a way to distinguish directly observed structure from model judgment.
3. Graph construction with NetworkX
After extraction, Graphify merges nodes and edges into a NetworkX graph. The official site describes this as the stage where static analysis and semantic extraction are unified into a single graph representation.
This combined graph is the project’s core data structure. It allows Graphify to represent:
- code-to-code relationships such as calls and imports
- code-to-doc links
- code-to-paper links
- code-to-diagram links
- concept-to-concept semantic relations
In other words, Graphify is building a shared relational layer across implementation artifacts and explanatory artifacts.
4. Leiden clustering without embeddings
One of Graphify’s clearest architectural positions is its use of Leiden community detection without vector embeddings. The project’s Leiden documentation says Graphify runs Leiden directly on graph topology, rather than clustering embedded chunks.
The rationale given by the project is that embedding-driven pipelines can lose explicit structure, produce opaque groupings, and add extra infrastructure such as vector stores. Graphify instead uses edge density in the graph as the clustering signal.
The same documentation says semantic similarity can still participate through inferred edges like semantically_similar_to. Those inferred edges live in the same graph as structural edges, so Leiden can cluster around both architectural structure and conceptual affinity.
5. God nodes, surprise edges, and graph-guided querying
The project site says Graphify identifies high-degree “god nodes” at the center of a system and flags unexpected cross-file or cross-domain connections as surprises. In the Leiden documentation, these surprises are described as edges ranked highly by a composite method, with cross-domain links treated as especially interesting.
Graphify also frames the graph as a token-efficiency mechanism. Instead of passing a full codebase into a model, the assistant can query a relevant subgraph and work from a compressed structural summary.
What to Watch Next
Based on the current materials, the next things worth watching are:
- broader validation across more repositories and programming stacks
- how well the semantic layer handles noisy or incomplete documentation
- whether graph-guided workflows become a more common alternative to embedding-heavy code RAG
- deeper integrations with assistant environments beyond the currently highlighted tools
Conclusion
Graphify is best understood as a multi-modal codebase knowledge graph builder, not a generic visualization package. Its architecture combines deterministic Tree-sitter parsing, semantic extraction over non-code materials, graph construction in NetworkX, and Leiden clustering over topology rather than embeddings.
That combination makes it an interesting project in the evolving code-intelligence stack. The strongest idea behind Graphify is not merely that it draws graphs, but that it gives AI coding assistants a more inspectable and structured representation of how a software project is built, documented, and explained.