Public note
DeepTutor Recasts the AI Tutor as an Agent-Native Learning Platform
DeepTutor is an open-source AI learning platform that evolved from a retrieval-augmented tutoring app into a modular system for chat, research, quiz generation, and persistent tutor agents.
Subheadline
HKUDS’ DeepTutor is no longer just a retrieval-augmented tutoring app. With its 1.0 beta series, the open-source project has been rebuilt as a broader agent-native learning system that combines chat, research, quiz generation, persistent tutor agents, and knowledge-base tooling in one stack.
Lead
Most AI tutor projects start with a familiar pitch: upload some documents, ask questions, and get answers back with citations. DeepTutor still does that, but its latest redesign aims much higher. The project from HKUDS now presents itself as an agent-native personalized learning assistant, built not as a single chat interface but as a multi-surface platform for learning workflows.
That shift matters because education software is increasingly colliding with agent software. Users do not just want a bot that answers a question; they want a system that can help them solve problems step by step, build quizzes from source materials, turn notes into structured study plans, remember long-term goals, and even maintain distinct AI tutors with different personalities. DeepTutor’s beta releases suggest the team is trying to assemble exactly that kind of environment.
At a Glance
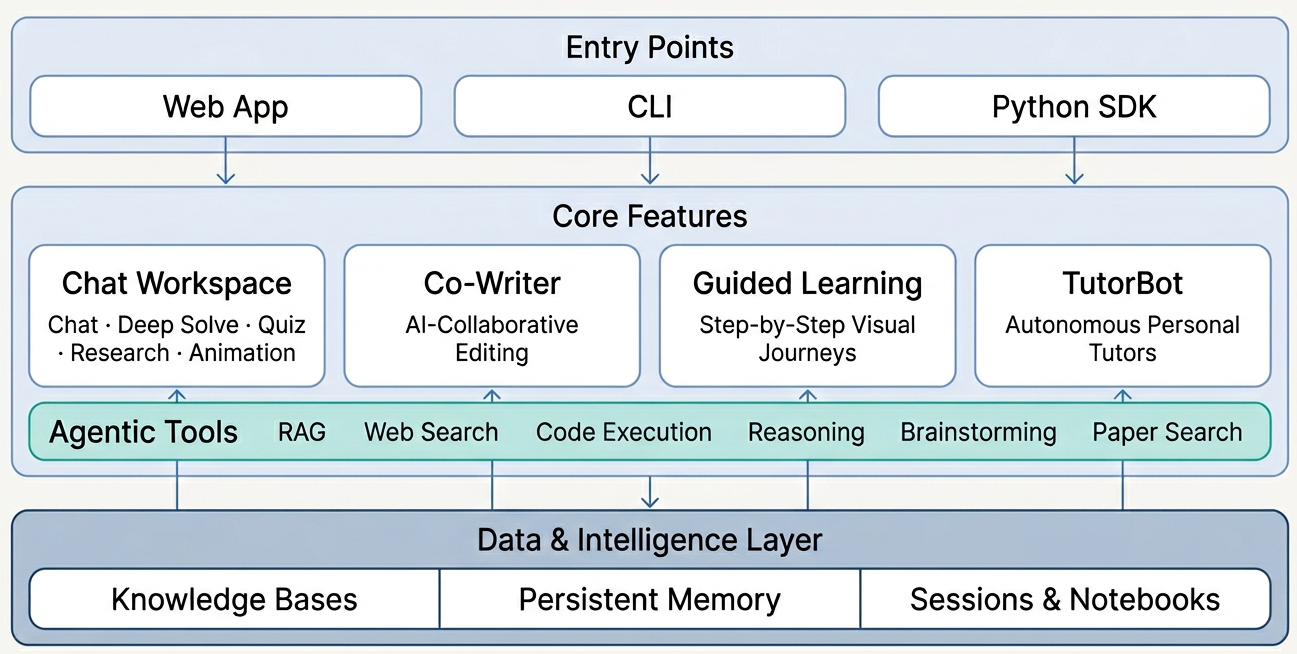
- DeepTutor’s v1.0.0 beta series marks a ground-up rewrite from a monolithic RAG tutor into an agent-native learning platform.
- The system uses a two-layer plugin model built around Tools and Capabilities.
- It exposes three entry points: a CLI, a WebSocket API, and a Python SDK.
- The main workspace unifies five modes in one thread: Chat, Deep Solve, Quiz Generation, Deep Research, and Math Animator.
- DeepTutor also includes persistent memory, knowledge bases, guided learning flows, and multi-instance TutorBots.
- The latest beta, released on April 10, 2026, added embedding progress tracking and automatic retries for HTTP 429 rate limits.
What Happened
The big news is architectural. In its April 4, 2026 beta-1 release, DeepTutor introduced what the project calls a “brand new” architecture: a rebuilt application shell, a two-layer plugin system, and unified access through CLI, WebSocket, and SDK interfaces. The release notes describe the project as a rewrite that moves DeepTutor away from a single monolithic tutoring flow and toward a more modular platform for learning agents.
Subsequent beta releases have focused on making that foundation more usable. The April 8 beta-3 release removed the LiteLLM dependency in favor of native OpenAI and Anthropic SDK integrations, while expanding provider compatibility through an OpenAI-compatible provider layer. The April 10 beta-4 release added real-time embedding progress reporting, exponential backoff for HTTP 429 responses during embedding, and onboarding improvements for cross-platform dependency installation.
Taken together, those updates show a project in transition from an interesting academic-style demo into a tool that is trying to survive real-world setup friction, model-provider variation, and longer user sessions.
Key Facts / Comparison
| Area | What DeepTutor Does | Why It Matters |
|---|---|---|
| Core architecture | Uses a two-layer plugin model of Tools + Capabilities | Separates low-level actions from higher-level learning workflows |
| Entry points | Supports CLI, WebSocket API, and Python SDK | Makes the system usable by humans, apps, and other agents |
| Main workspace | Keeps five modes in one thread | Reduces context switching between tutoring, solving, research, and quiz creation |
| Knowledge layer | Builds RAG-ready knowledge bases from PDFs, Markdown, and text | Lets users ground tutoring on their own materials |
| Personalization | Maintains persistent memory and TutorBots | Pushes the platform beyond stateless chat interactions |
| Latest beta focus | Improves embedding visibility, retries, and onboarding | Signals a move toward more reliable production-style usage |
Background and Context
DeepTutor sits in a crowded field of AI education tools, but its design choices put it closer to the emerging “agent platform” category than to a simple study chatbot. The project combines a learning interface, a document-backed retrieval system, persistent user memory, and agent orchestration patterns that are more often associated with developer tooling.
The project’s own documentation emphasizes that one conversation can move across multiple modes without losing context. In practical terms, that means a learner might start in chat, switch into a multi-agent problem-solving flow, generate a quiz based on the same knowledge base, and then push the result into notebooks or a guided learning path. That kind of continuity is one of the platform’s clearest differentiators.
There is also a notable shift in the knowledge-base strategy. The beta-1 release notes say the team temporarily simplified the RAG pipeline to LlamaIndex only, removing LightRAG and RAG-Anything support for the time being to focus on stability. That is a common sign of a project trying to narrow scope while rebuilding a more dependable core.
Why This Matters
DeepTutor matters because it reflects a broader change in how AI learning products are being built.
Instead of treating tutoring as a single prompt-response loop, the project treats learning as a sequence of connected tasks:
- asking questions,
- solving problems with explicit planning,
- generating assessments,
- researching source material,
- writing and rewriting notes,
- and maintaining long-term learner context.
That model is closer to how real students work. They rarely just “chat.” They read, annotate, quiz themselves, revisit weak spots, and return over time. A platform that can preserve context across those behaviors has a stronger claim to usefulness than one that produces good one-off answers.
For developers and institutions, the multi-entry design is equally important:
- CLI makes DeepTutor scriptable and automatable.
- WebSocket API opens the door to interactive app integrations.
- Python SDK makes it easier to embed in other workflows or research systems.
Insight and Industry Analysis
The strongest idea inside DeepTutor is not any single feature. It is the attempt to unify pedagogy, agent orchestration, and knowledge management into one coherent stack.
That gives the project two potential advantages. First, it can offer richer educational workflows than a general-purpose chatbot. Second, it may appeal to builders who want an open-source foundation for specialized learning products rather than a finished consumer app.
But that ambition also creates risk. Projects that try to be chat app, agent framework, RAG system, notebook, research assistant, quiz engine, and tutor runtime all at once can become hard to maintain and harder to explain. DeepTutor’s recent release notes suggest the team understands that challenge: many recent changes are not flashy features, but integration cleanup, provider rationalization, and reliability fixes.
That is usually a healthy sign. In open-source infrastructure-style projects, the real story is often not the demo surface but the reduction of operational friction.
Pros and Cons
Pros
- Broad learning workflow coverage: Chat, problem solving, research, quiz generation, and guided learning are connected in one environment.
- Agent-native design: The Tools/Capabilities split gives the system a clearer architecture than many monolithic tutor apps.
- Strong personalization direction: Persistent memory and TutorBots support longer-term learning relationships.
- Flexible interfaces: CLI, WebSocket, and SDK support make the project useful beyond the browser UI.
- Grounded study support: Knowledge bases and notebooks make it easier to learn from user-provided material rather than generic model output.
Cons
- Complexity overhead: The platform’s breadth may be intimidating for casual users who only want lightweight tutoring.
- Beta-stage rough edges: The project itself warns that some UI interactions and edge cases may still contain bugs.
- RAG scope contraction: Temporarily narrowing to LlamaIndex improves stability, but it also reduces flexibility versus the project’s broader ambition.
- Setup burden remains real: Even with guided onboarding, multi-provider AI stacks and local dependencies are still more demanding than SaaS tutoring apps.
Technical Deep Dive
At the architecture level, DeepTutor routes multiple entry points into a shared orchestration layer. According to the project’s AGENTS.md, a ChatOrchestrator sits between the outer interfaces and the selected capability. That makes the system look less like a single assistant and more like a runtime that dispatches tasks into specialized modules.
Capability-level workflow
| Capability / Module | Role |
|---|---|
| Chat | General conversation with tool augmentation |
| Deep Solve | Multi-agent problem solving with planning, investigation, solution, and verification |
| Quiz Generation | Generates assessments grounded in a knowledge base |
| Deep Research | Breaks topics into subtopics and dispatches parallel research across RAG, web, and papers |
| Math Animator | Converts math concepts into visual animations and storyboards powered by Manim |
Knowledge system details
The knowledge layer is more than a file upload box. The project documentation says new documents are processed incrementally, merged into the existing knowledge graph or index state, and deduplicated to avoid unnecessary reprocessing. That matters for users who are building a growing corpus over time rather than starting from scratch in every session.
Guided learning and memory
DeepTutor’s guided learning flow turns materials into multi-step learning paths, generating interactive pages for each knowledge point and preserving progress across sessions. Meanwhile, the memory system maintains both a summary of learning progress and a profile representing preferences, goals, and communication style.
TutorBot as a persistent agent layer
One of the more distinctive ideas in the stack is TutorBot. Rather than being framed as just another chat persona, TutorBot is presented as a persistent autonomous tutor with its own workspace, memory, personality, and skills. In other words, DeepTutor is not only offering task-based capabilities; it is also offering durable agent identities inside the learning environment.
What to Watch Next
- Whether DeepTutor can turn its beta architecture into a stable 1.0 release without overwhelming users with complexity.
- How quickly LightRAG and other removed knowledge-base options return after the stability-focused simplification.
- Whether TutorBot evolves into the platform’s defining feature rather than just an interesting side module.
- How far the CLI and SDK ecosystem grows among developers building custom education workflows.
- Whether the project can translate architectural ambition into measurable learning outcomes, not just richer demos.
Conclusion
DeepTutor is most interesting when viewed not as a chatbot, but as an attempt to build a full operating environment for AI-assisted learning. Its recent rewrite shows a project reaching beyond retrieval-based tutoring toward something more ambitious: a modular platform where chat, research, assessment, memory, and persistent tutor agents can all reinforce one another.
That ambition comes with obvious trade-offs. The system is broader, more complex, and still in beta. But if HKUDS can keep reducing friction while preserving the coherence of its learning workflows, DeepTutor could become one of the more notable open-source experiments in turning AI tutoring into a true agent-native product category.